
















Предисловие
Благодарности
Об этой книге
Глава 1. Что такое интеллектуальный Интернет?
1.1. Примеры интеллектуальных вебприложений
1.2. Базовые элементы интеллектуальных приложений
1.3. Что могут выиграть приложения от интеллектуальности?
1.3.1. Сайты социальных сетей
1.3.2. Гибридные вебприложения (мэшапы)
1.3.3. Порталы
1.3.4. Викисайты
1.3.5. Сайты общего доступа к медиафайлам
1.3.6. Онлайнигры
1.4. Как встроить интеллект в мое приложение?
1.4.1. Анализ функциональности и данных
1.4.2. Получение дополнительных данных из Интернета
1.5. Машинное обучение, интеллектуальный анализ данных и так далее
1.6. Восемь заблуждений насчет интеллектуальных приложений
1.6.1. Заблуждение 1: данные достоверны
1.6.2. Заблуждение 2: логический вывод осуществляется мгновенно
1.6.3. Заблуждение 3: размер данных не имеет значения
1.6.4. Заблуждение 4: масштабируемость решения - не проблема
1.6.5. Заблуждение 5: одна хорошая библиотека годится на все случаи
1.6.6. Заблуждение 6: время вычислений известно
1.6.7. Заблуждение 7: чем сложнее модель, тем лучше
1.6.8. Заблуждение 8: существуют модели без систематической ошибки
1.7. Заключение
1.8. Ссылки
Глава 2. Поиск
2.1. Поиск с применением библиотеки Lucene
2.1.1. Программный код библиотеки Lucene
2.1.2. Анализ основных этапов поиска
2.2. Зачем нужен поиск вне индексов?
2.3. Уточнение результатов поиска на основе анализа ссылок
2.3.1. Алгоритм PageRank
2.3.2. Вычисление вектора PageRank
2.3.3. alpha: эффект телепортации между вебстраницами
2.3.4. Основные сведения о степенном методе
2.3.5. Объединение оценок индексирования и оценок PageRank
2.4. Уточнение результатов поиска на основе анализа экранных данных
2.4.1. Первое знакомство с анализом экранных данных
2.4.2. Применение наивного байесовского классификатора
2.4.3. Объединение оценок индексирования Lucene, вектора PageRank и данных о переходах пользователя по ссылкам
2.5. Ранжирование документов Word, PDF и других документов без ссылок
2.5.1. Введение в алгоритм DocRank
2.5.2. Внутренние механизмы алгоритма DocRank
2.6. Проблемы масштабной реализации
2.7. Получили ли вы то, что искали? Точность и выборка
2.8. Заключение
2.9. Сделать
2.10. Ссылки
Глава 3. Выработка предложений и рекомендаций
3.1. Музыкальный интернет-магазин: основные понятия
3.1.1. Понятия расстояния и сходства
3.1.2. Подробнее о вычислении сходства
3.1.3. Какую из формул вычисления сходства предпочесть?
3.2. Как работают системы выработки рекомендаций?
3.2.1. Рекомендации на основе сходства пользователей
3.2.2. Рекомендации на основе сходства предметов
3.2.3. Рекомендации на основе контента
3.3. Выработка рекомендаций по друзьям, статьям и новостным сообщениям
3.3.1. Знакомство с сайтом MyDiggSpace.com
3.3.2. Нахождение друзей
3.3.3. Внутренние механизмы класса DiggDelphi
3.4. Рекомендации фильмов на сайте, подобном сайту Netflix.com
3.4.1. Введение в наборы данных о кинофильмах и рекомендателях
3.4.2. Нормализация данных и коэффициенты корреляции
3.5. Масштабная реализация и вопросы оценки
3.6. Заключение
3.7. Сделать
3.8. Ссылки
Глава 4. Кластеризация: объединение в группы
4.1. Необходимость кластеризации
4.1.1. Группы пользователей на вебсайте (конкретный случай)
4.1.2. Нахождение групп с помощью SQL-предложения order by
4.1.3. Нахождение групп путем сортировки массива
4.2. Обзор алгоритмов кластеризации
4.2.1. Классификация алгоритмов кластеризации по структуре кластеров
4.2.2. Классификация алгоритмов кластеризации по типу и структуре данных
4.2.3. Классификация алгоритмов кластеризации по размеру обрабатываемых данных
4.3. Алгоритмы связей
4.3.1. Дендрограмма: базовая структура данных кластера
4.3.2. Знакомство с алгоритмами связей
4.3.3. Алгоритм одной связи
4.3.4. Алгоритм средней связи
4.3.5. Алгоритм минимального остовного дерева
4.4. Алгоритм k-средних
4.4.1. Первое знакомство с алгоритмом k-средних
4.4.2. Внутренние механизмы работы алгоритма k-средних
4.5. Устойчивая кластеризация, использующая связи (ROCK)
4.5.1. Введение в алгоритм ROCK
4.5.2. Почему ROCK - это надежно?
4.6. DBSCAN
4.6.1. Первое знакомство с алгоритмами на основе плотности
4.6.2. Внутренние механизмы алгоритма DBSCAN
4.7. Вопросы кластеризации очень больших наборов данных
4.7.1. Вычислительная сложность
4.7.2. Большая размерность
4.8. Заключение
4.9. Сделать
4.10. Ссылки
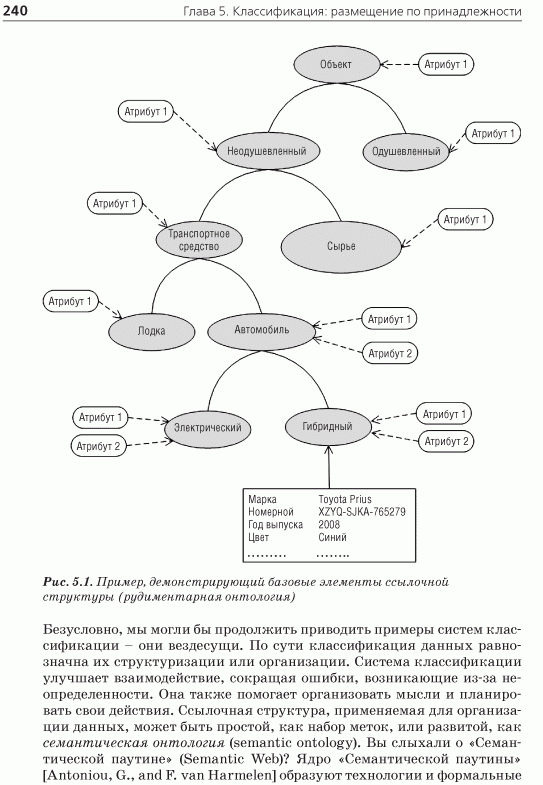
Глава 5. Классификация: размещение по принадлежности
5.1. Необходимость классификации
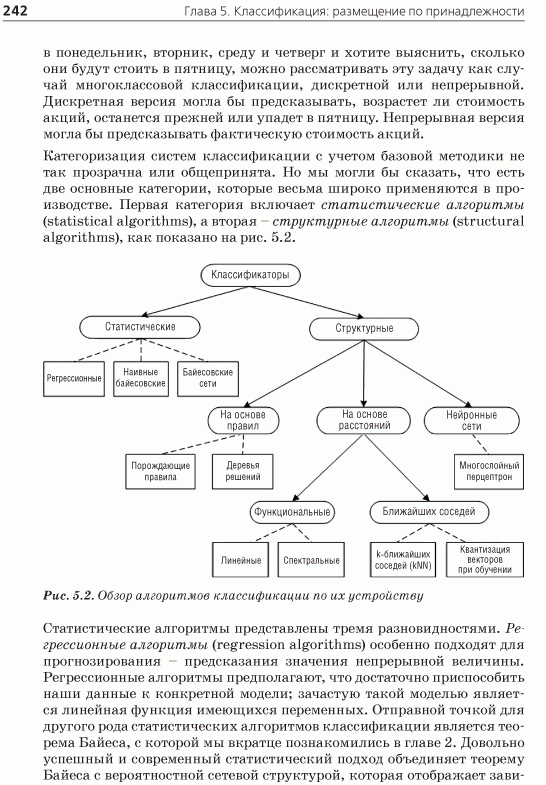
5.2. Обзор классификаторов
5.2.1. Алгоритмы структурной классификации
5.2.2. Статистические алгоритмы классификации
5.2.3. Жизненный цикл классификатора
5.3. Автоматическая категоризация почтовых сообщений и фильтрация спама
5.3.1. Наивная байесовская классификация
5.3.2. Классификация по правилам
5.4. Обнаружение мошенничества с помощью нейронных сетей
5.4.1. Сценарий выявления мошенничества в транзакционных данных
5.4.2. Обзор нейронных сетей
5.4.3. Детектор мошенничества на основе нейронной сети в действии
5.4.4. Анатомия нейронной сети детектора мошенничества
5.4.5. Базовый класс для создания универсальных нейронных сетей
5.5. Можно ли доверять полученным результатам?
5.6. Классификация очень больших наборов данных
5.7. Заключение
5.8. Сделать
5.9. Ссылки
Глава 6. Объединение классификаторов
6.1. Кредитоспособность: анализ примера объединения классификаторов
6.1.1. Краткое описание данных
6.1.2. Создание искусственных данных для реальных задач
6.2. Оценка кредитоспособности с помощью единственного классификатора
6.2.1. Основы применения наивного байесовского классификатора
6.2.2. Основы применения дерева решений
6.2.3. Основы применения нейронных сетей
6.3. Сравнение классификаторов в применении к одним и тем же данным
6.3.1. Тест Макнемара
6.3.2. Тест на разность пропорций
6.3.3. Q-тест Кохрана и F-тест
6.4. Bagging - самонастраиваемое объединение
6.4.1. Bagging-классификатор в действии
6.4.2. Заглянем внутрь bagging-классификатора
6.4.3. Ансамбли классификаторов
6.5. Boosting - итеративный подход к улучшению
6.5.1. Boostingклассификатор в действии
6.5.2. Заглянем внутрь boosting-классификатора
6.6. Заключение
6.7. Сделать
6.8. Ссылки
Глава 7. Все вместе: интеллектуальный новостной портал
7.1. Обзор функциональности
7.2. Получение и обработка контента
7.2.1. На старт, внимание, краулинг!
7.2.2. Обзор предварительных условий поиска
7.2.3. Используемый по умолчанию набор извлеченных и обработанных новостных сообщений
7.3. Поиск новостных сообщений
7.4. Распределение по новостным категориям
7.4.1. Порядок имеет значение!
7.4.2. Классификация с помощью класса NewsProcessor
7.4.3. Знакомьтесь: классификатор
7.4.4. Стратегия классификации: выход за пределы низкоуровневой категоризации
7.5. Формирование групп новостей с помощью класса NewsProcessor
7.5.1. Кластеризация обычных новостных сообщений
7.5.2. Кластеризация новостных сообщений в категории новостей
7.6. Динамический контент на базе пользовательских оценок
7.7. Заключение
7.8. Сделать
7.9. Ссылки
Приложение A. Введение в BeanShell
A.1. Что такое BeanShell?
A.2. Зачем нужен язык BeanShell?
A.3. Выполнение BeanShell
A.4. Ссылки
Приложение B. Краулинг
B.1. Обзор компонентов поискового робота
B.1.1. Этапы краулинга
B.1.2. Наш простой поисковый робот
B.1.3. Поисковые роботы с открытым исходным кодом
B.2. Ссылки
Приложение C. Памятка по математике
C.1. Векторы и матрицы
C.2. Измерение расстояний
C.3. Развитые матричные методы
C.4. Ссылки
Приложение D. Обработка естественных языков
Приложение E. Нейронные сети
Алфавитный указатель
